



Globally-Asynchronous Locally-Synchronous (GALS)-based Programmable Low Power High Performance Security Processor
![]()
![]()
Processor Architecture
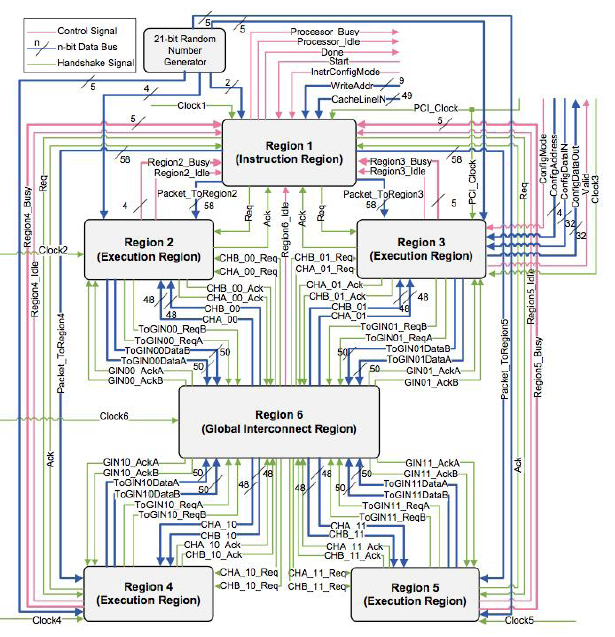
The Globally Asynchronous Locally Synchronous- based (GALS) Security Processor is based on the Transport Triggered Architecture (TTA) - a dataflow-oriented architecture - which offers higher throughput due to the fact that it parallels the nature of cryptographic algorithms. Internally, the processor is partitioned into 6 regions (1 instruction region, 4 execution regions, and 1 region for interconnection among regions). Each execution region contains a number of Function Units (FU) typically encountered in the implementation of encryption algorithms. FUs grouped in the same execution region are selected to have comparable delay performance. Moreover, each region is governed by its own clock frequency, which allows each FU to run at its own frequency and this – again – contributes to higher throughput. In addition, the decoupled structure of the GALS units makes it possible to clock gate idle regions and thereby reducing the amount of dissipated power. Finally, the asynchrony of regions, in addition to a novel data scrambling technique, renders the processor higher immunity against side channel attacks.
Project Objectives
The current project aims at producing a prototype for a Globally-Asynchronous Locally-Synchronous (GALS)-based Programmable Low-Power High-Performance Security Process (LP HP SP) ). The main approach for enhancing performance in the proposed processor is to move along three axes; instruction level parallelism axis, data level parallelism axis and asynchrony axis. For the instruction level parallelism, effort will be made to optimize the number of command-buses between the instruction region and the execution regions, thereby contolling the number of instructions that could be sent for execution in parallel. For the data level parallelism, aim is to optimize the number of data-buses, with the result that more data packets would be moving in parallel among the regions. Finally, for asynchrony, we seek to optimize the number of execution regions thereby adjusting the number of Function Units (FUs) that run at their own clock frequency, and hence yielding optimized performance since they do not have to wait idle until the next clock.
Gantt Chart and Project Deliverables
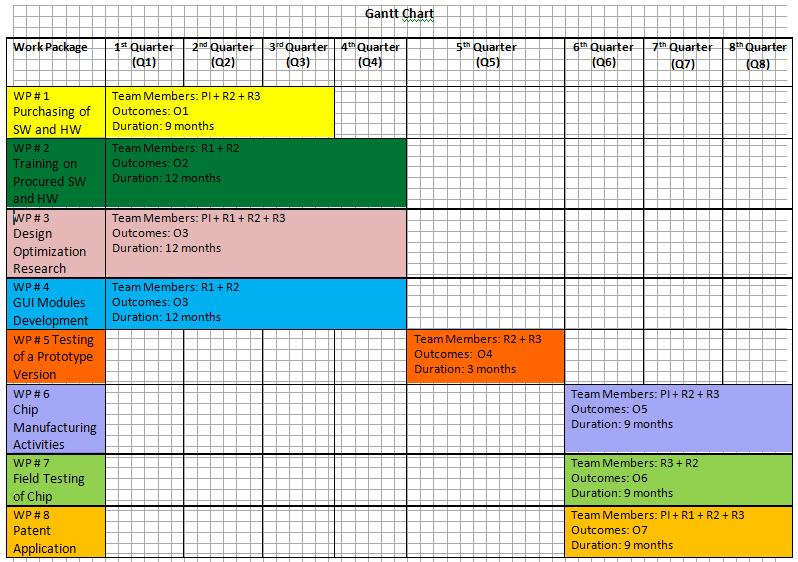
List of Deliverables
Deliverables for Review#1 (End of Q2):
Technical + Financial Report for Period Q1+Q2, with reference to:
WP1-D1 – Book of Specifications for Equipment & Software Procurement
Deliverables for Review#2 (End of Q4):
Technical + Financial Report for Period Q3+Q4, with reference to:
WP1-D2 – Equipment & Software delivery by Bidder(s) receiving purchase order
WP1-D3 – RAs and TAs trained according to bid specifications
WP1-D4 – Equipment & Software recorded as institutional assets
WP2-D1 – Training Plan for Project
WP2-D2 – List of Team Members who received training and list of training courses
WP3-D1 – Optimized processor design with respect to # of regions, # of buffers and distribution of FUs
WP3-D2 – Revised processor design with asynchronicity considered
WP4-D1 – Code for communicating between PC and security processor
WP4-D2 – Code for graphical display of user interface screen
Deliverables for Review#3 (End of Q6):
Technical + Financial Report for Period Q5+Q6, with reference to:
WP5-D1 – Code for emulated security processor
WP5-D2 – RTL for designed FPGA-based processor
WP5-D3 – Performance results of FPGA-based processor using software tools and from FPGA Development Kit
WP6-D1 – ASIC-ready RTL design
Publications from M.Sc. and Ph.D. Research
Deliverables for Review#4 (End of Q8):
Technical + Financial Report for Period Q7+Q8, with reference to:
WP6-D2 – Mask files for 1stTapeout
WP6-D3 – Mask files for 2ndTapeout
WP7-D1 – Test Board ready for use
WP7-D2 –1stTapeout Test results
WP7-D3 –2ndTapeout Test results
WP8-D2 – Patent Document
WP8-D3 – Patent registration receipt
Publications from M.Sc. and Ph.D. Research
Published Work:
1 - El-Hadidi MT, Elsayed HM, Aslan H, Osama K. Structured design approach for an optimal programmable synchronous security processor. H. Kim and D. Choi (Ed), Information Security Applications 2015: 313-325.
2 - Elsayed HM, El-Hadidi MT, Osama K, Aslan H. Multi-objective genetic algorithm-based optimization of an asynchronous data-flow security processor. Proceedings 2016 33rd National Radio Science Conference (NRSC2016) 2016: 168-177.
3 - El-Hadidi MT, Elsayed HM, Bakr M, Aslan HK, Optimization of a Novel Programmable Data-Flow Crypto Processor Using NSGA-II Algorithm, Journal of Advanced Research, Elsevier, 2017 (https://doi.org/10.1016/j.jare.2017.11.002).
Electronic Research Institute (ERI)
National Telecommunications Institute (NTI)